
AMD 锐龙8745H/8845H 通过LM Studio使用GPU运行deepseek指南
之前写了一篇AMD 锐龙8745H/8845H 通过ollama使用GPU运行deepseek指南,有小伙伴说有没有通过LM Studio使用GPU运行deepseek的指南,这里安排上,通过LM Studio使用GPU运行deepseek还是比较简单的,比起ollama操作起来省事点,不需要再去下载Rocm库了。
安装LM Studio
访问官网https://lmstudio.ai/ ,根据自己的操作系统下载安装包,点击安装包下一步 下一步即可
安装后打开界面如下
如果打开后语言不是中文可以点击右下角的⚙进行设置
下载模型
注意在软件内搜索模型需要翻墙,后面也会说一下不翻墙怎么下载
使用快捷键ctrl+shift+m 可以打开模型搜索界面或者在软件主页面点击右上角搜索框
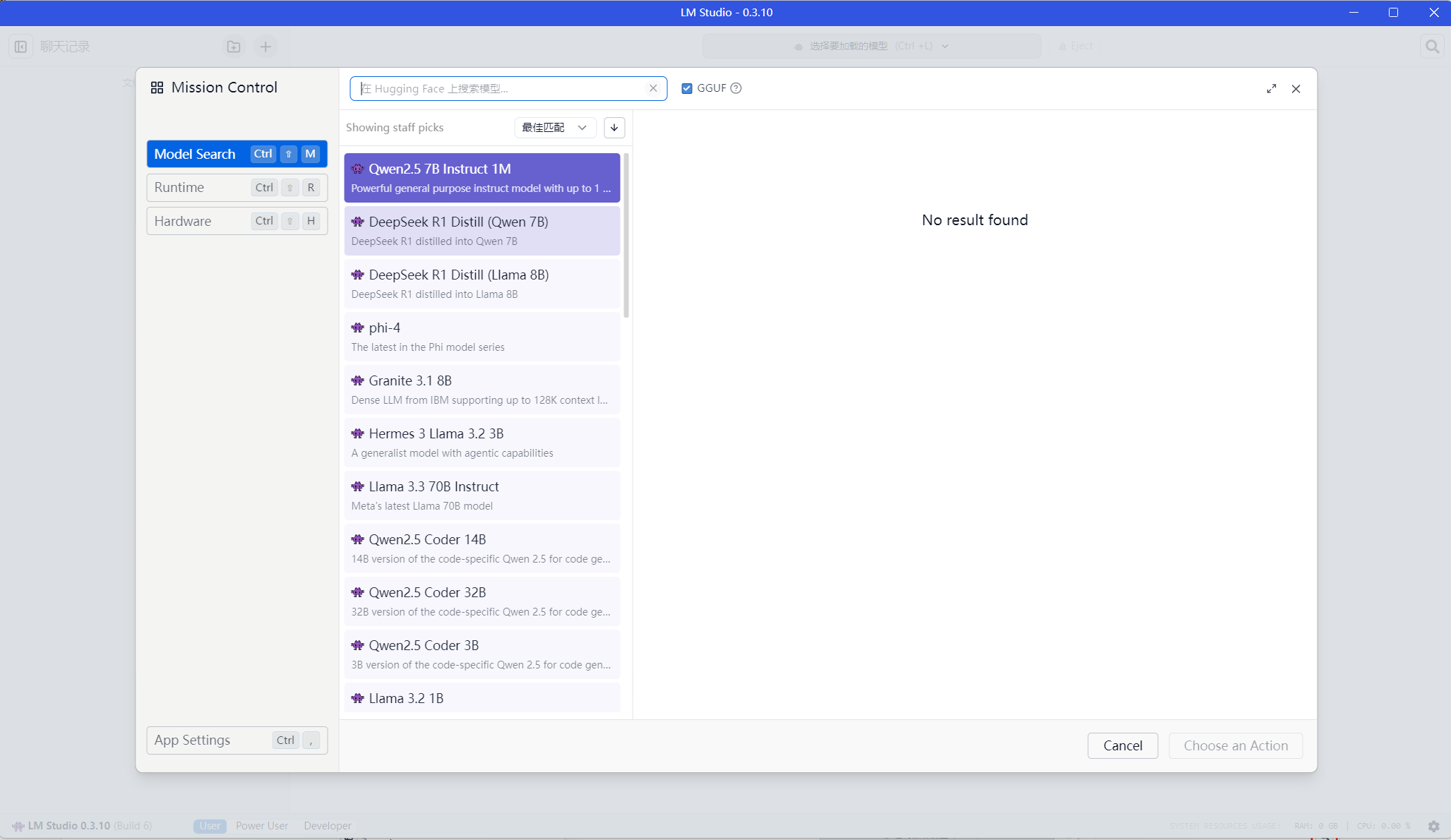
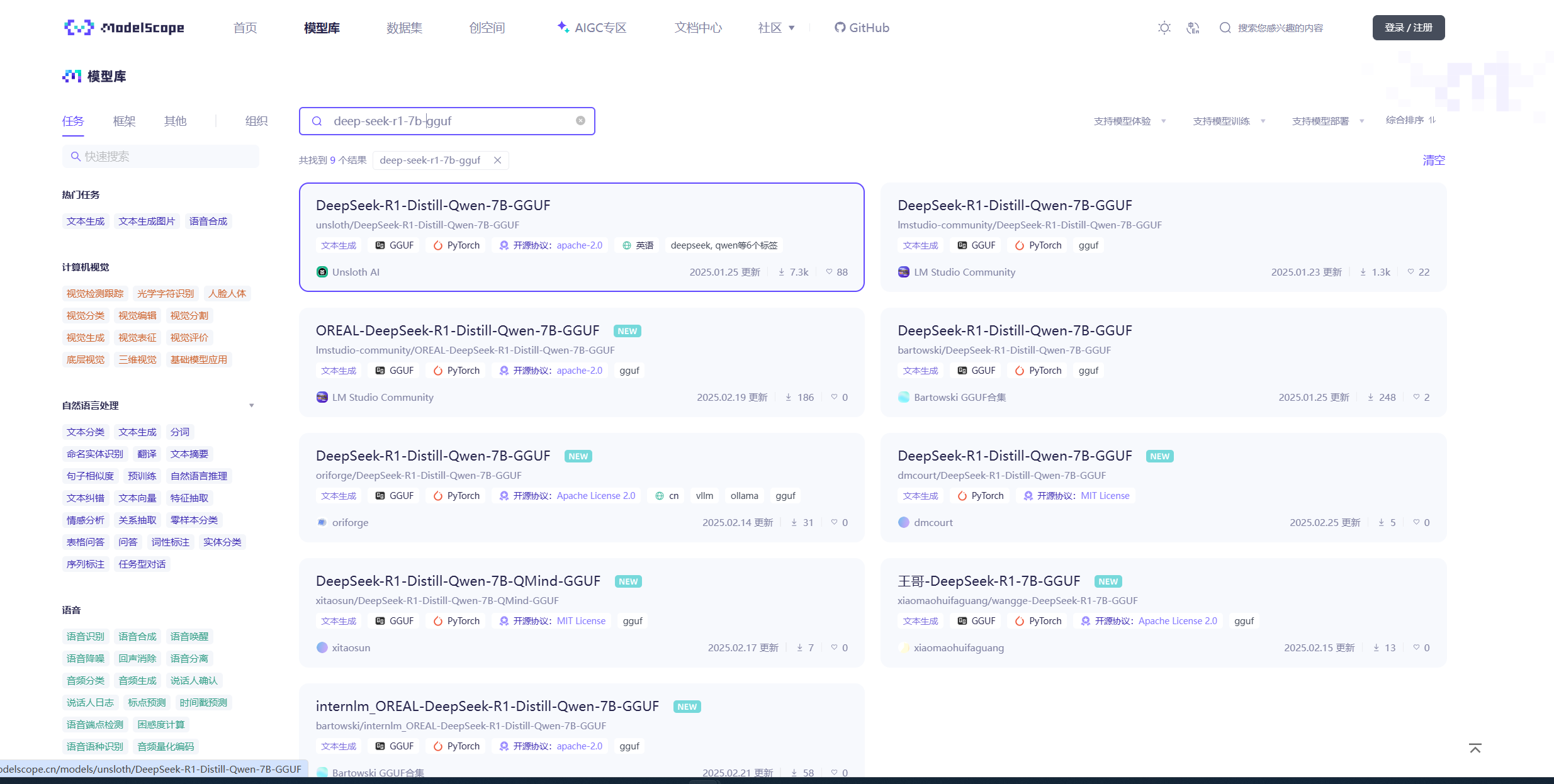
这里我们搜索deepseek-r1,会出现很多模型,选择一个合适的点击后在页面右下角可以进行下载。这里我们选择DeepSeek R1 Distill (Qwen 7B)
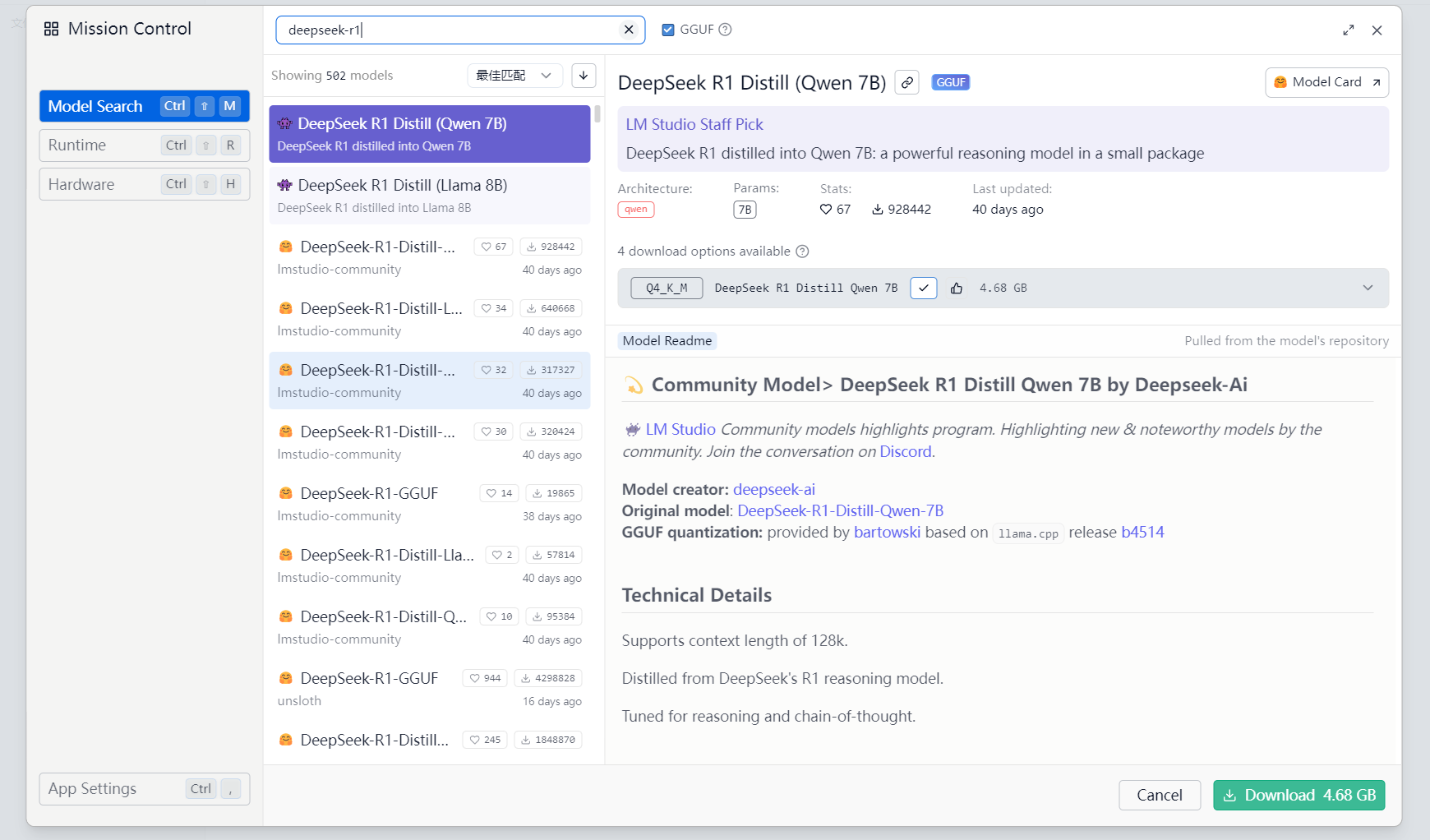
我们还可以访问https://huggingface.co/models 去查找模型,要选择名称中带GGUF的模型
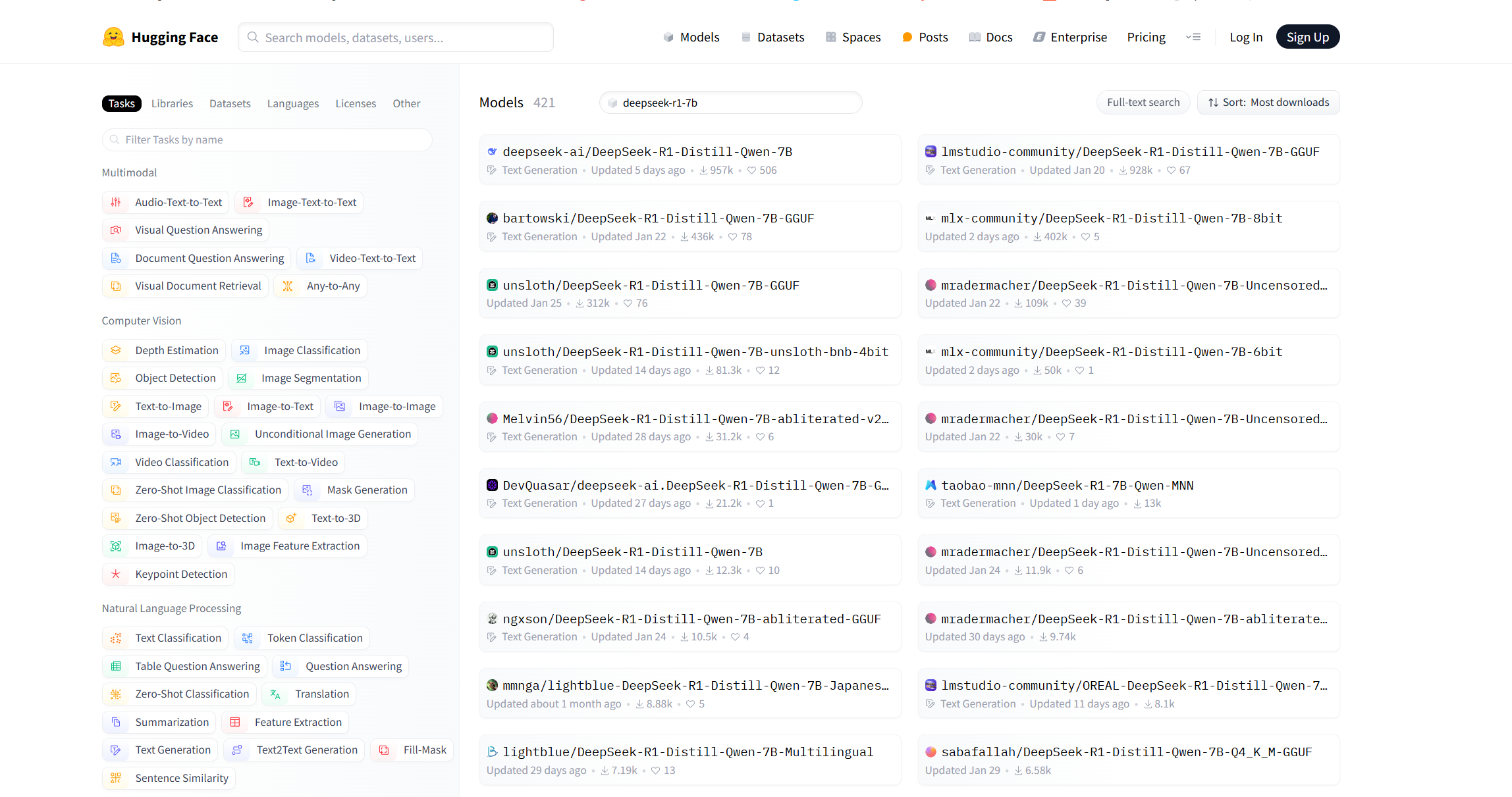
找到模型后我们可以点击use this modle 选择LM Studio使用,然后在
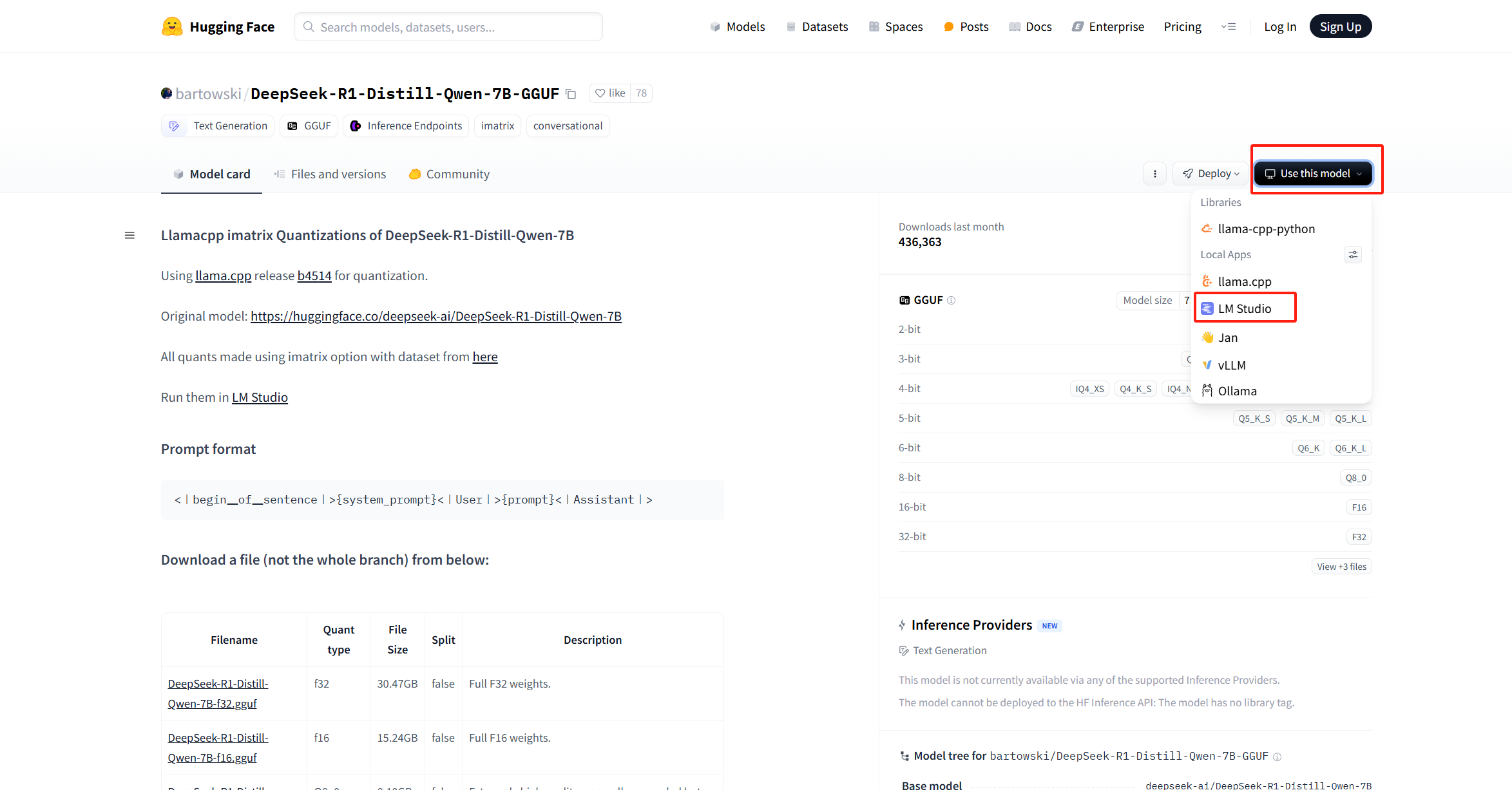

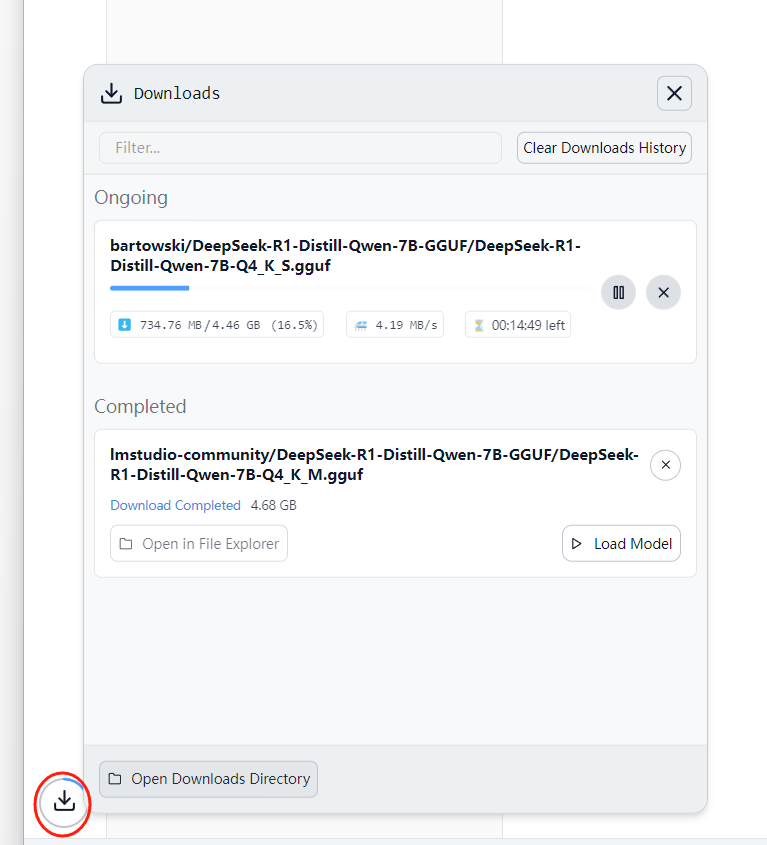
下载模型时候我们可以切换到power user 查看模型的下载信息
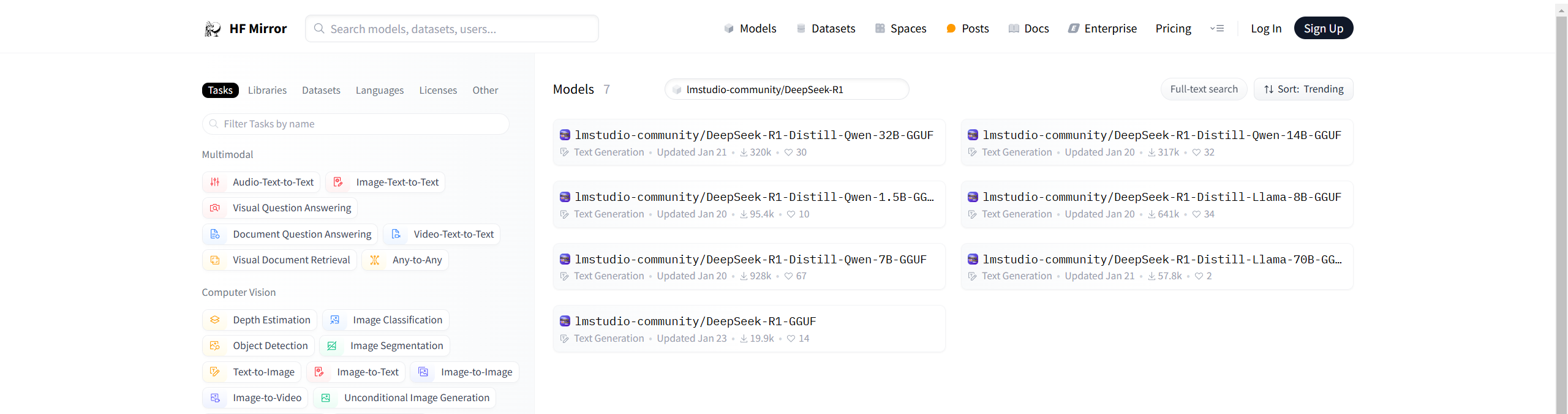
如果电脑没有翻墙 那么软件内搜索是用不了的,这个时候可以使用 huggingface 的镜像站,可以使用https://hf-mirror.com/

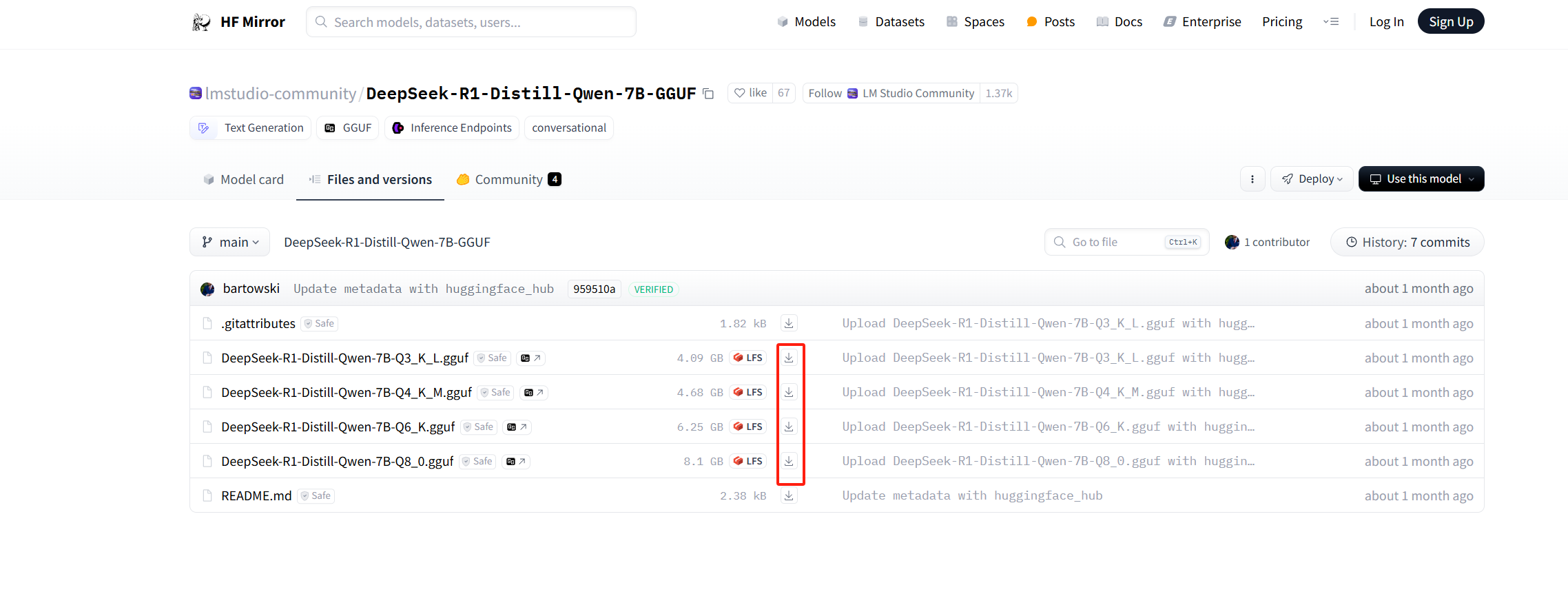
搜索模型,在模型页面去下载gguf文件,这里搜的是lmstudio-community/DeepSeek-R1
如果下载速度慢可以试试魔塔的https://modelscope.cn/model
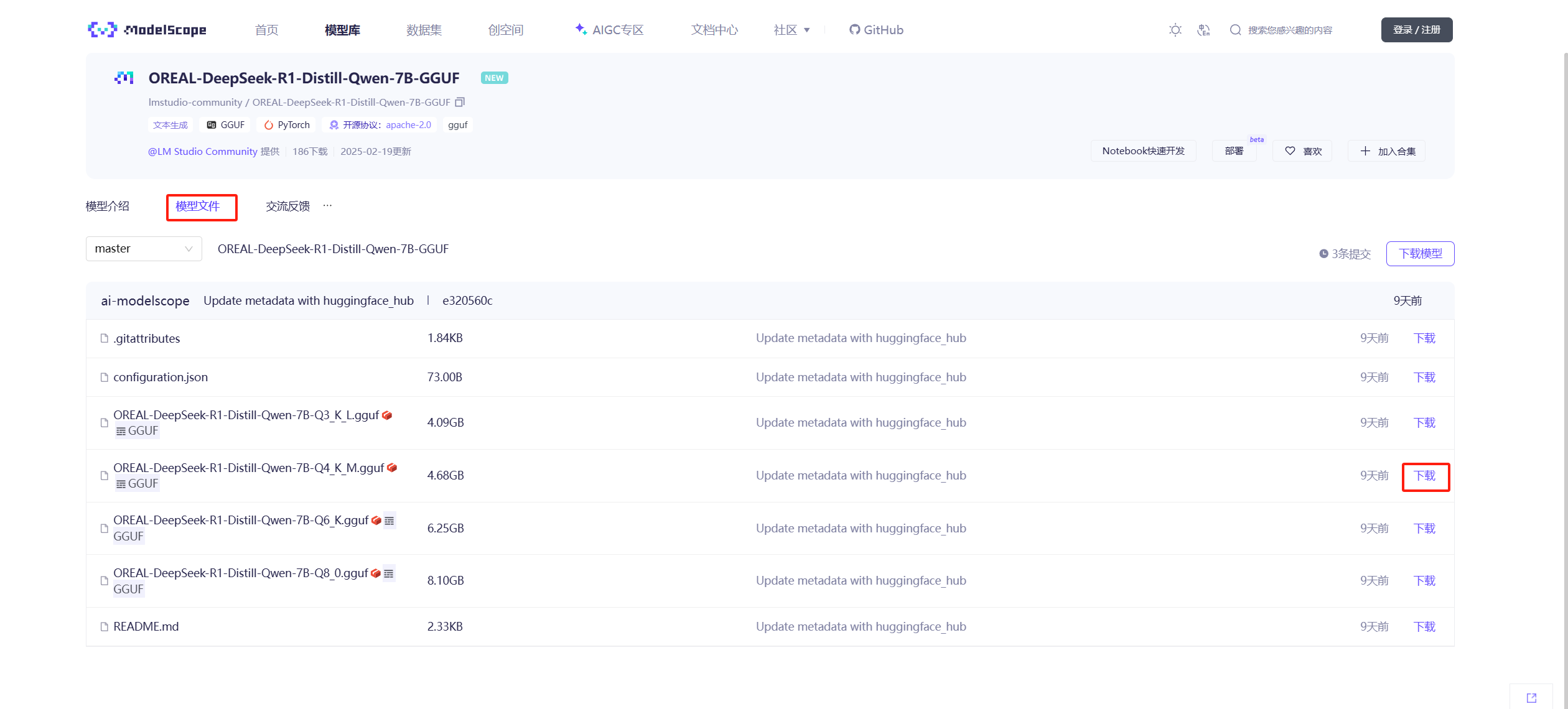
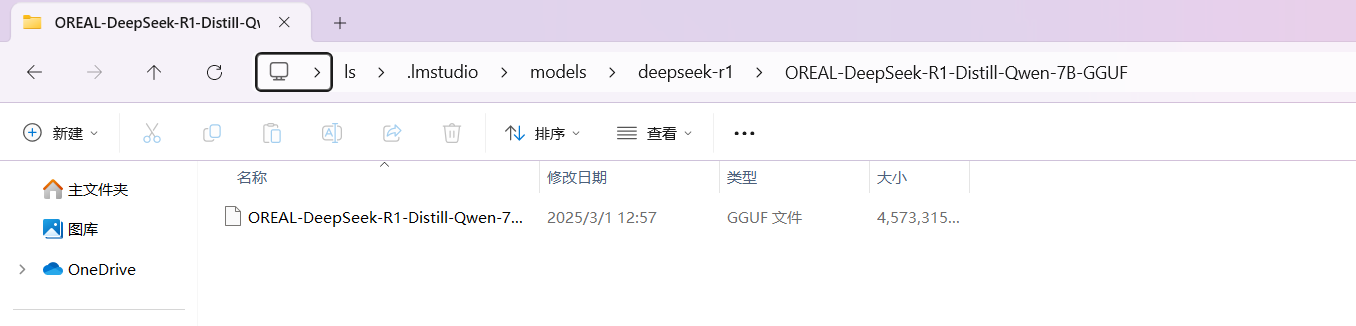
下载完成后打开C:\Users\[你的用户名]\.lmstudio\models目录,在目录里创建一个目录 比如deepseek-r1,在deepseek-r目录中在创建一个文件夹,文件夹和你模型名称一致,比如我这里就叫OREAL-DeepSeek-R1-Distill-Qwen-7B-GGUF ,将之前下载的gguf文件放在该文件夹内
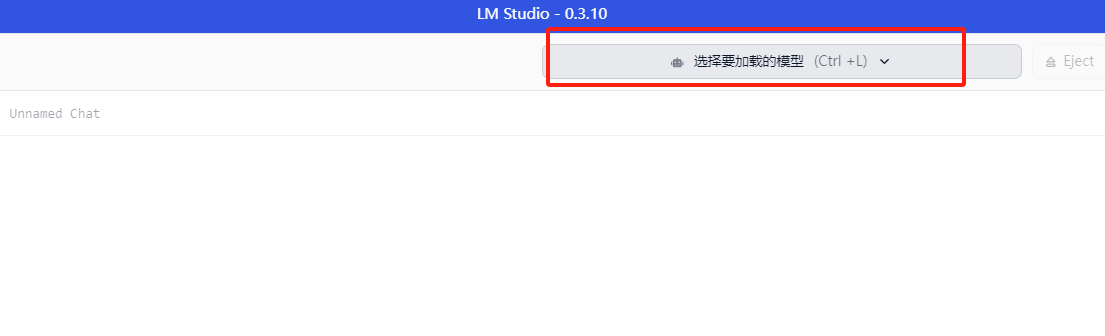
这时候打开LM Studio, 点击选择要加载的模型我们就可以看到OREAL-DeepSeek-R1-Distill-Qwen-7B-GGUF这个模型了

使用GPU运行模型
默认使用的是cpu和内存运行,速度大概9-10token/s

要使用gpu运行模型,我们需要在选择模型时候勾选手动选择模型加载参数,然后点击模型右边的 >
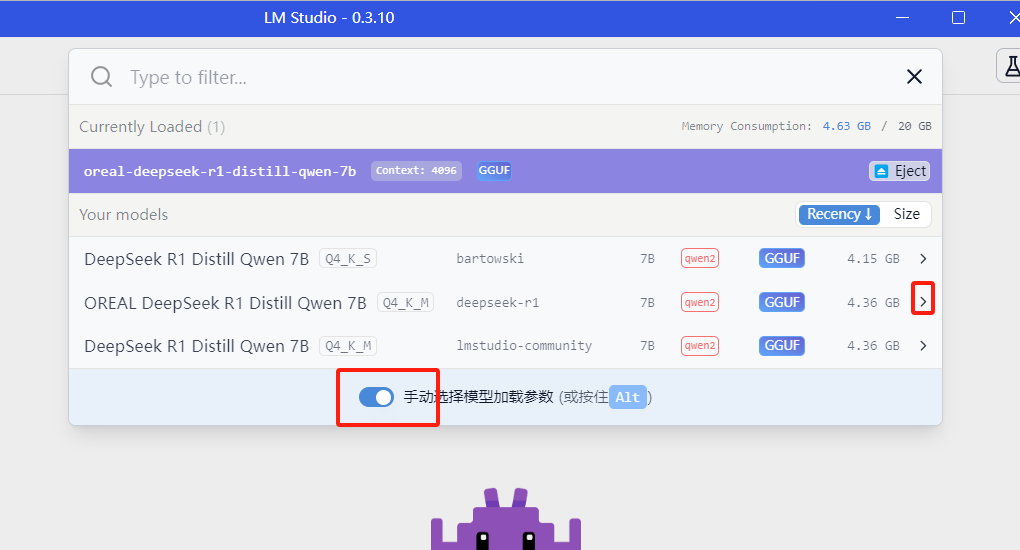
选择GPU卸载 并加载模型
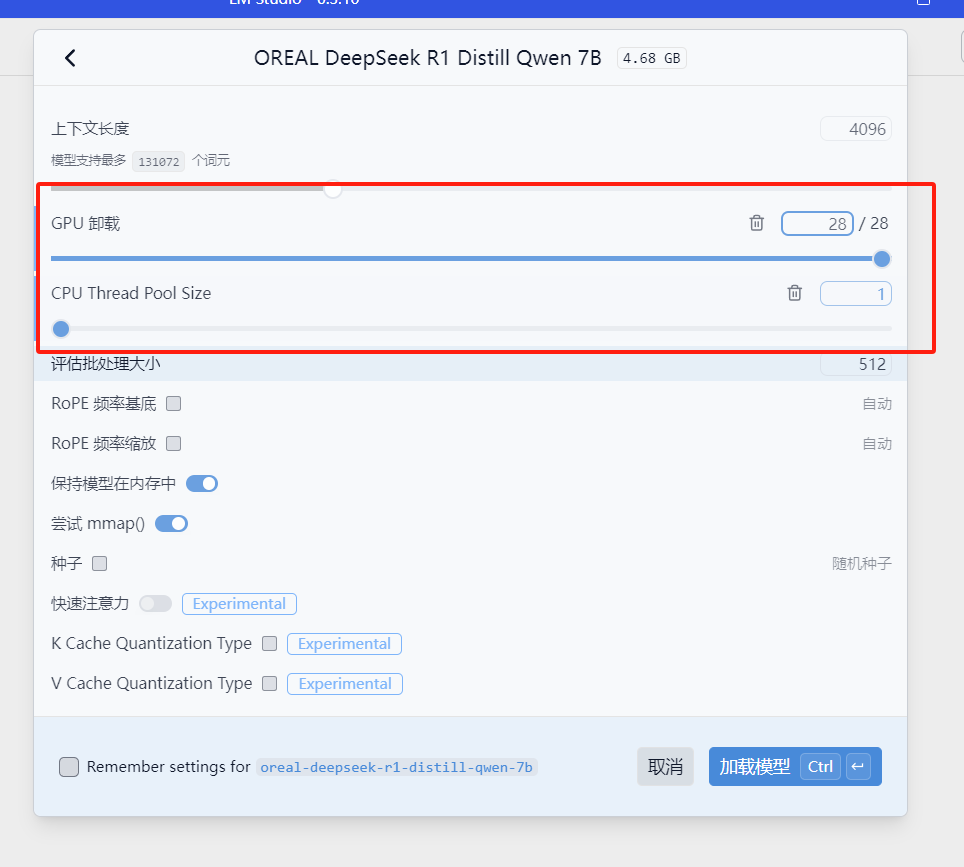
我们在运行模型就可以发现GPU负载已经被拉满,生成速度大概14-15 token/sec
