蹭一波通义千问QwQ-32B的热度。前几天阿里巴巴正式发布并开源全新推理模型通义千问QwQ-32B,主打“高性能+低门槛”特性。该模型基于320亿参数规模,在数学推理、代码生成及通用任务中表现亮眼,综合性能对标DeepSeek-R1(6710亿参数,激活量370亿),还是使用我的AMD 锐龙8745H 小主机,ollma上用起来比较简单,LM Studio上需要改一下设置。
ollama
我的机器上 ollama 测试下来 BIOS中核显分配 2g 内存可以运行qwb:32b (Q4_K_M) ,
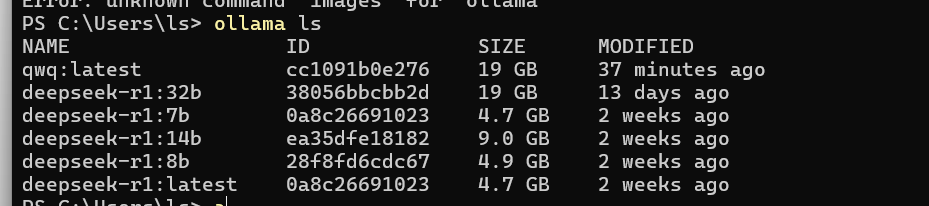
启动后可以看到内存使用 28.4/29.8GB
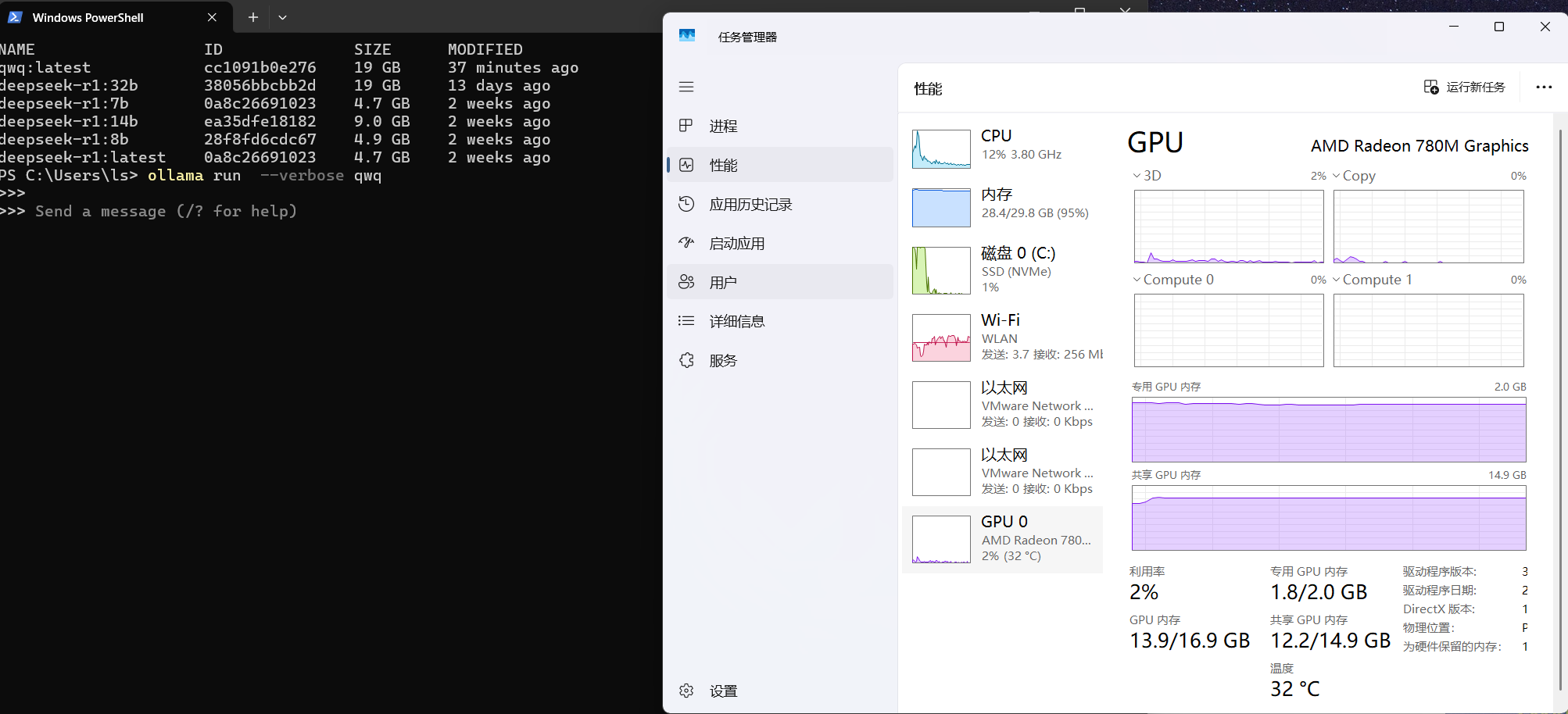
推出使用ollama ps 查看一下情况
1 | C:\Users\ls> ollama ps |
使用过程中cpu/gpu占用
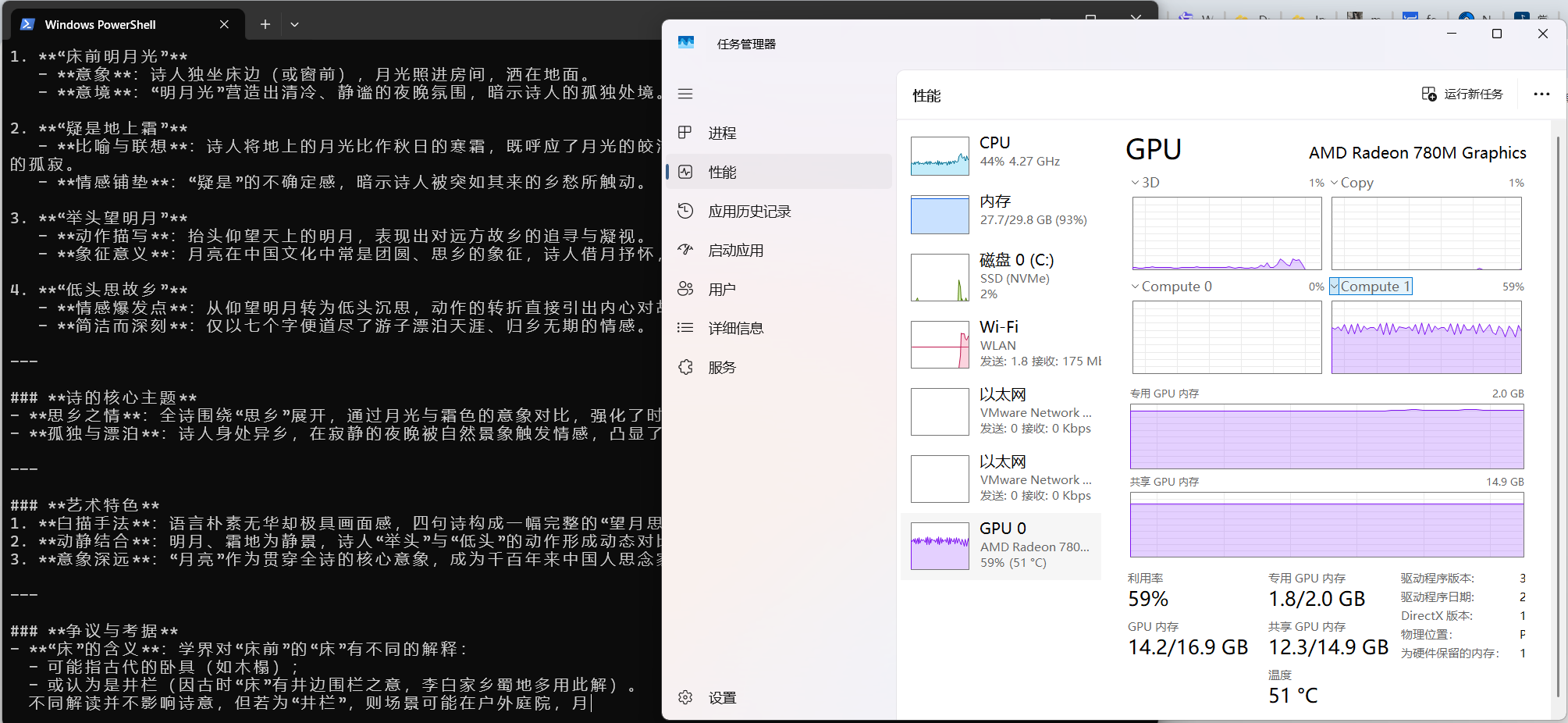
用起来速度 2.4 token/s ,是有点慢
1 | PS C:\Users\ls> ollama run --verbose qwq |
LM Studio
这里使用了两个模型分别是 qwq-32b-q4_k_m和qwq-32b-q2_k的
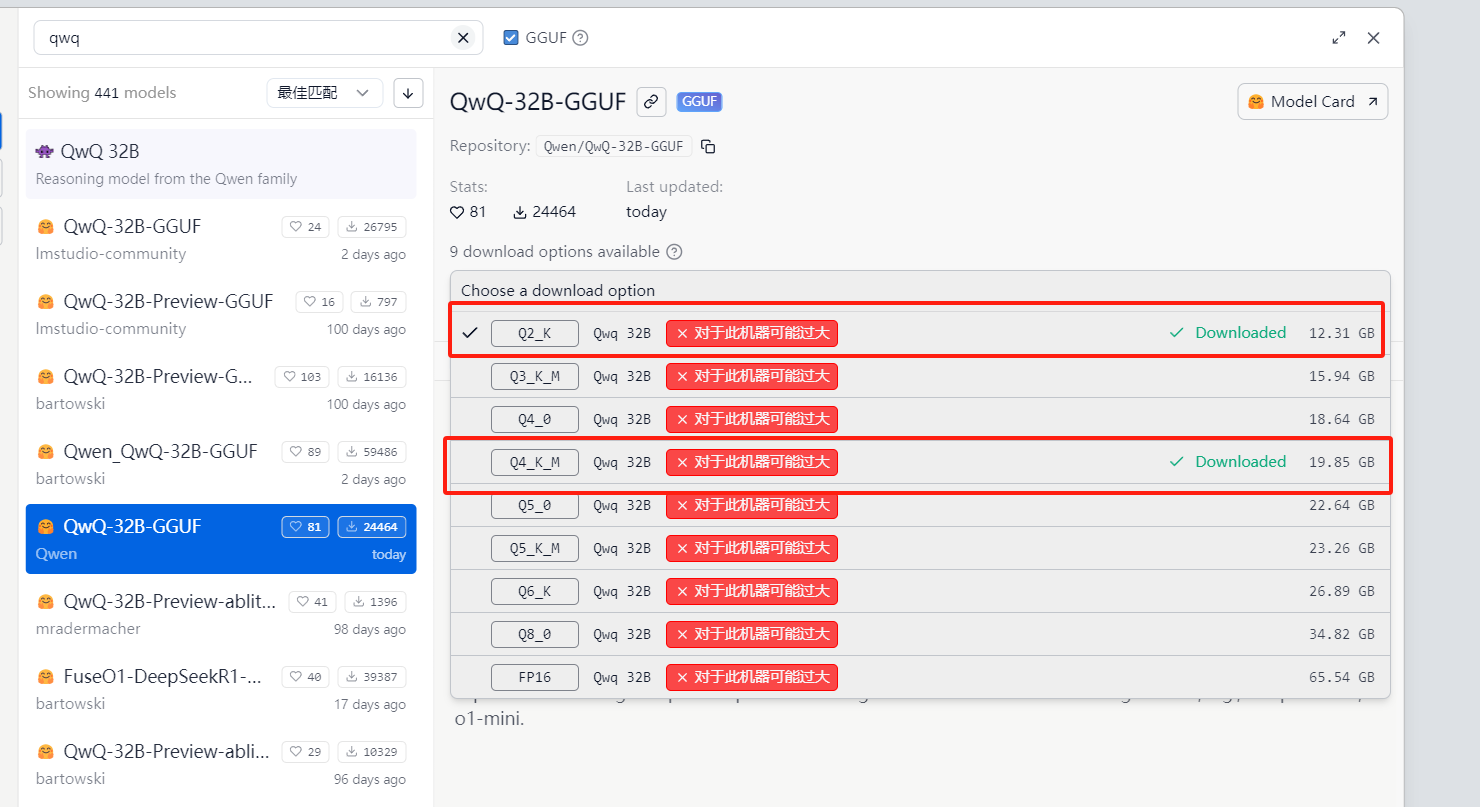
使用qwq-32b@q2_k
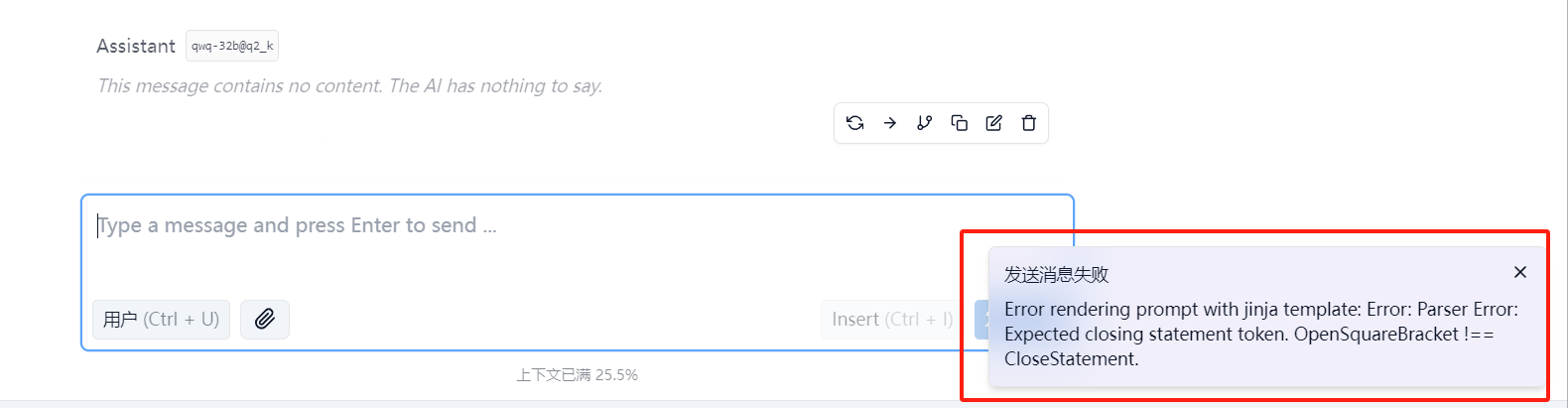
默认大概率会出现这个报错发送消息失败 Error rendering prompt with jinja template: Error: Parser Error: Expected closing statement token. OpenSquareBracket !== CloseStatement
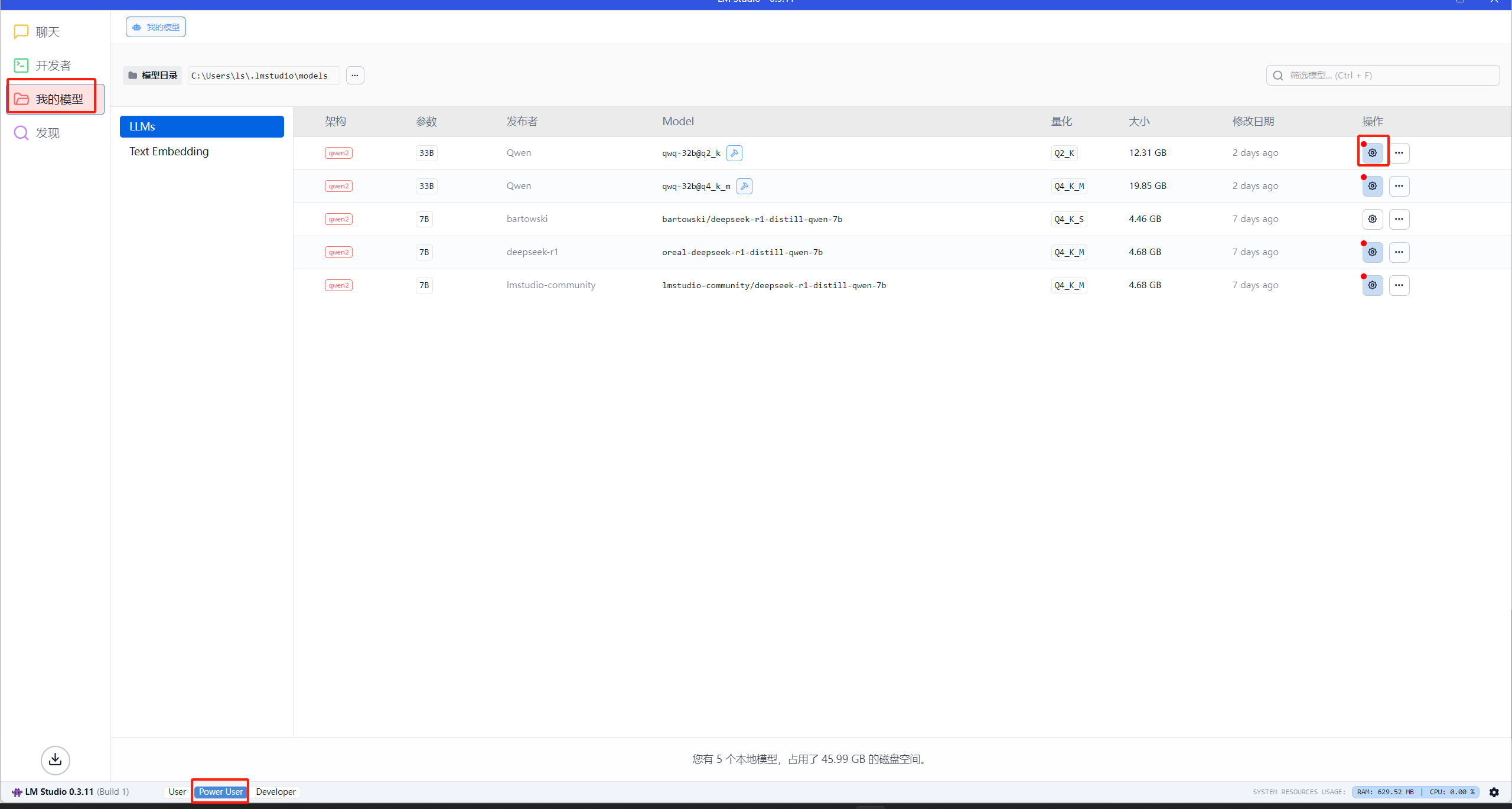
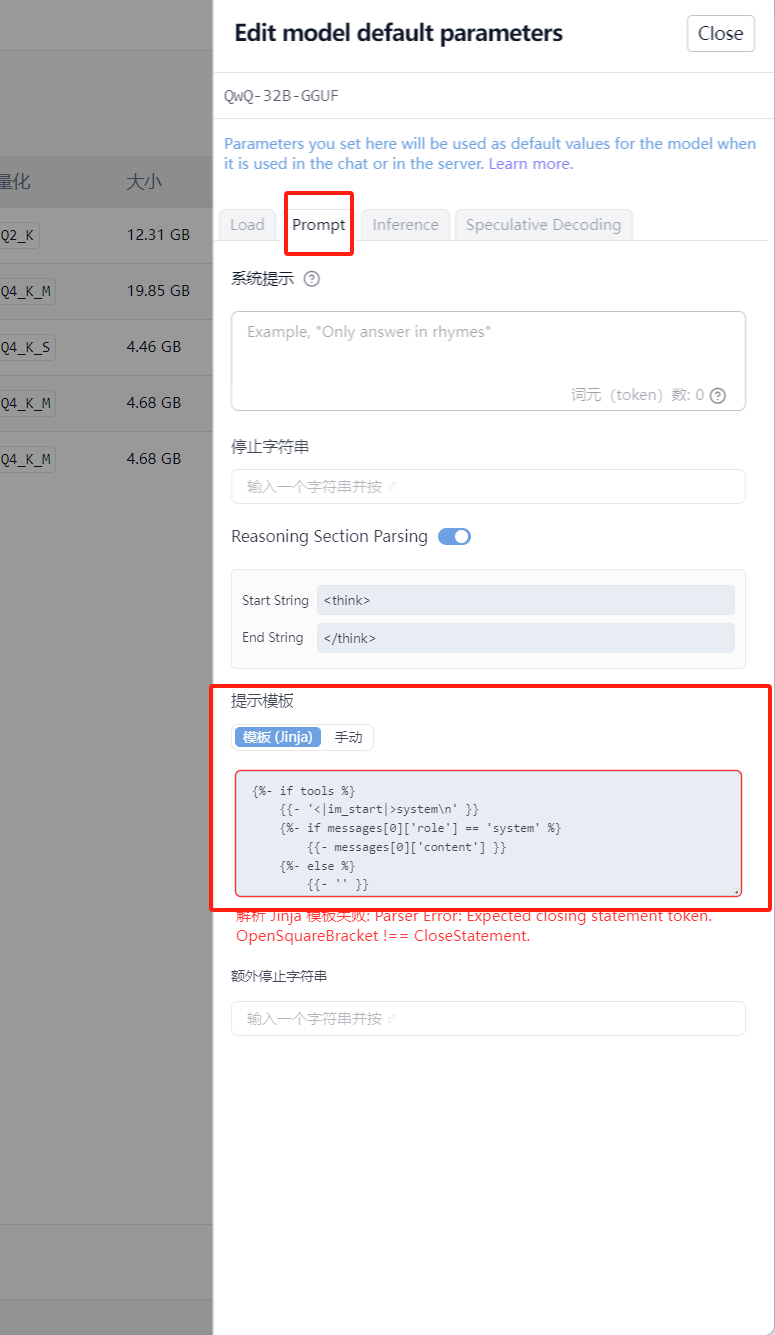
这个时候需要转到������我的模型并单击 QwQ-32B 模型旁边的⚙️,编辑“jinja”提示模板如下
1 | {%- if tools %} {{- '<|im_start|>system\n' }} {%- if messages[0]['role'] == 'system' %} {{- messages[0]['content'] }} {%- else %} {{- '' }} {%- endif %} {{- "\n\n# Tools\n\nYou may call one or more functions to assist with the user query.\n\nYou are provided with function signatures within <tools></tools> XML tags:\n<tools>" }} {%- for tool in tools %} {{- "\n" }} {{- tool | tojson }} {%- endfor %} {{- "\n</tools>\n\nFor each function call, return a json object with function name and arguments within <tool_call></tool_call> XML tags:\n<tool_call>\n{\"name\": <function-name>, \"arguments\": <args-json-object>}\n</tool_call><|im_end|>\n" }} {%- else %} {%- if messages[0]['role'] == 'system' %} {{- '<|im_start|>system\n' + messages[0]['content'] + '<|im_end|>\n' }} {%- endif %} {%- endif %} {%- for message in messages %} {%- if (message.role == "user") or (message.role == "system" and not loop.first) %} {{- '<|im_start|>' + message.role + '\n' + message.content + '<|im_end|>' + '\n' }} {%- elif message.role == "assistant" and not message.tool_calls %} {%- set content = (message.content.split('</think>')|last).lstrip('\n') %} {{- '<|im_start|>' + message.role + '\n' + content + '<|im_end|>' + '\n' }} {%- elif message.role == "assistant" %} {%- set content = (message.content.split('</think>')|last).lstrip('\n') %} {{- '<|im_start|>' + message.role }} {%- if message.content %} {{- '\n' + content }} {%- endif %} {%- for tool_call in message.tool_calls %} {%- if tool_call.function is defined %} {%- set tool_call = tool_call.function %} {%- endif %} {{- '\n<tool_call>\n{"name": "' }} {{- tool_call.name }} {{- '", "arguments": ' }} {{- tool_call.arguments | tojson }} {{- '}\n</tool_call>' }} {%- endfor %} {{- '<|im_end|>\n' }} {%- elif message.role == "tool" %} {%- if (loop.index0 == 0) or (messages[loop.index0 - 1].role != "tool") %} {{- '<|im_start|>user' }} {%- endif %} {{- '\n<tool_response>\n' }} {{- message.content }} {{- '\n</tool_response>' }} {%- if loop.last or (messages[loop.index0 + 1].role != "tool") %} {{- '<|im_end|>\n' }} {%- endif %} {%- endif %} {%- endfor %} {%- if add_generation_prompt %} {{- '<|im_start|>assistant\n' }} {%- endif %} |
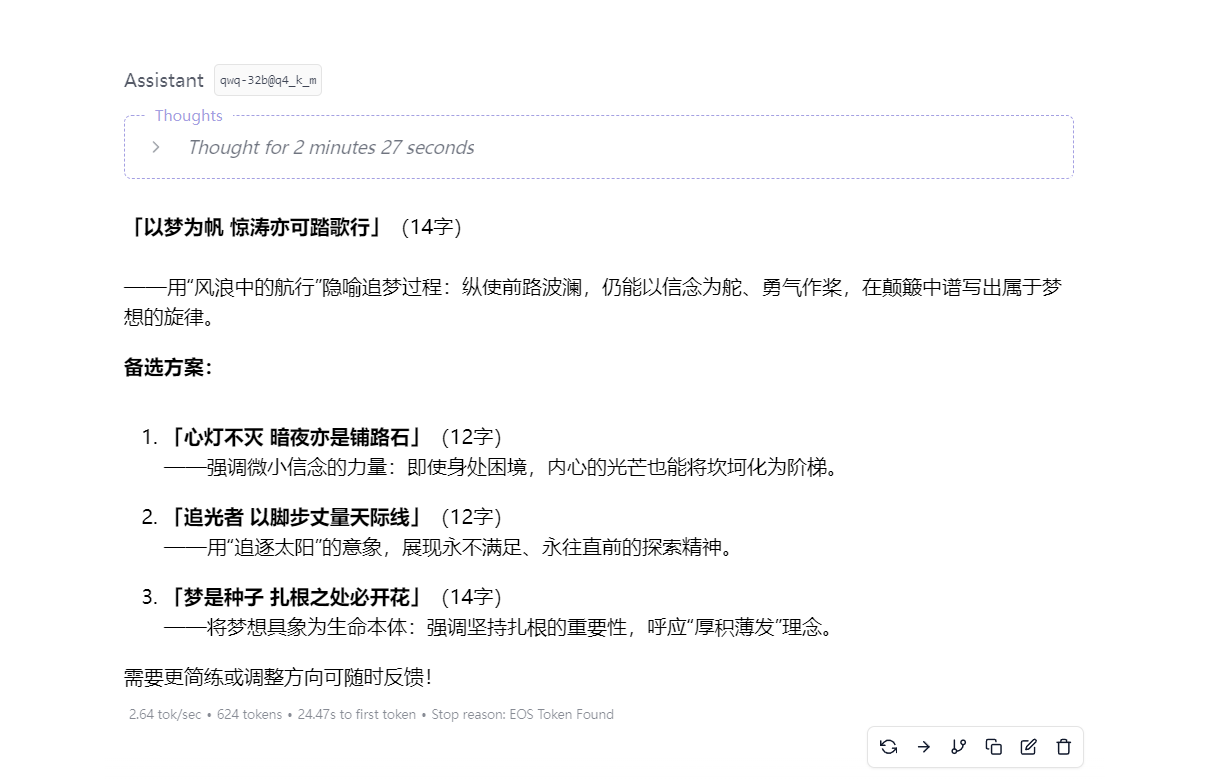
执行速度如下,快的时候能跑5.4 token/s , 马马虎虎吧,反正也只是个人玩具

使用qwq-32b@q4_k_m
qwq-32b@q4_k_m运行起来就慢了很多,只能跑到2.64 token/s ,注意也要修改jinjia模板